- Richard LAURENT
Merci Nicolas. - 8:35 pm -
 Sylvia Kesbi
Sylvia Kesbi
@DataLeTemps Outil #ddj. Pour de la récupération de données basique, un outil simple https://magic.import.io - 8:36 pm -
 Isabelle Reffas Journaliste
Isabelle Reffas Journaliste
Sur ce site gratuit où Nicolas KB est intervenu il y a plein d'exercices pratiques de stats et avec excel - 8:36 pm -
Isabelle Reffas Journaliste
-

jeudi 30 octobre 2014
mercredi 22 octobre 2014
Créez votre première API
Lancement de la barre d'outils
Pour créer une API de kimono de n'importe quelle page Web, accédez au site Web que vous souhaitez obtenir des données de et cliquez sur le bookmarklet kimonify . Cela fera apparaître la barre d'outils de kimono: La barre d'outils est votre panneau de contrôle central lors de la création de l'API. Il vous permet d'organiser et de nommer vos données, de visualiser différents formats de sortie et finaliser / créer votre API. Les boutons / actions disponibles sur la barre d'outils comprennent:
La barre d'outils est votre panneau de contrôle central lors de la création de l'API. Il vous permet d'organiser et de nommer vos données, de visualiser différents formats de sortie et finaliser / créer votre API. Les boutons / actions disponibles sur la barre d'outils comprennent:| Bouton | Nom | Description |
|---|---|---|
 | cercle de données | Représente les différents types de données par couleur et affiche le nombre d'éléments dans l'ensemble de données actuel. |
 | Nouveau type de données | Cliquez dessus pour lancer un nouveau type de données et commencer à ajouter à la nouvelle base de données |
 | Pagination | Si vous voulez kimono de suivre un / lien 'suivant' 'plus' pour obtenir des données de plusieurs pages avec structure semblable, cliquez sur ce lien puis sélectionnez que sur la page. En savoir plus en lisant la pagination |
 | Annuler | Si vous faites une erreur, cliquez sur Annuler pour revenir en arrière |
 | vue de l'extracteur | La vue par défaut, affichage de la page web et vos sélections |
 | vue de modèle de données | Montre comment les éléments que vous avez sélectionnés seront associés |
 | aperçu des données | Affiche un aperçu de la façon dont vos données seront regarder dans JSON, CSV ou RSS |
 | Terminé | Une fois que vous avez terminé de sélectionner les données que vous souhaitez, cliquez sur Terminé pour créer votre API |
Sélection d'éléments
Pour obtenir des données de la page, cliquez simplement dessus. Lorsque vous déplacez votre souris, vous remarquerez que le texte et les images sont mises en évidence dans la même couleur que le cercle de données dans la barre d'outils. Chaque fois que vous cliquez sur quelque chose de nouveau, kimono va ajouter cet élément à votre ensemble de données, et sera également suggérer des articles similaires à vous:
 ou
ou  . Vous pouvez également sélectionner des éléments supplémentaires qui ne sont pas proposées en cliquant sur eux que vous avez fait le premier.
. Vous pouvez également sélectionner des éléments supplémentaires qui ne sont pas proposées en cliquant sur eux que vous avez fait le premier.les types de données de ponte
Il est important que vous indiquiez à kimono quand vous voulez commencer à sélectionner un type de données différent. Pour ce faire, en cliquantà tout moment de lancer un nouveau type de données. Chaque type de données est représentée par un nouveau cercle de données / couleur dans la barre d'outils.Un seul type de données peut être actif à tout moment, et les éléments sur lesquels vous cliquez sur dans la page sera inclus que dans l'ensemble de données actif, pas les autres. Par exemple,
 indique trois types de données différents, chacun avec 5 éléments sélectionnés.
indique trois types de données différents, chacun avec 5 éléments sélectionnés.Vous pouvez nommer vos types de données en utilisant le champ de texte à côté des cercles de types de données ou de la vue du modèle de données (
).Suppression des types de données
Les types de données peuvent être effacées à tout moment en cliquant sur le petit bouton de suppression rouge qui apparaît en haut à droite de type de données lorsque vous utilisez votre souris pour planer au-dessus du point de type de données:
Les modèles de données et de l'Association
L'un des principes sous-jacents de la conception de kimono, c'est que nous ne voulons pas que vous devez penser sur le modèle de données. Vous devriez être en mesure de cliquer sur les informations que vous souhaitez sur la page, et kimono allez comprendre le reste.Le construits dans les algorithmes d'apprentissage peut associer des éléments sur les types de données et les organiser en collections. Cliquez sur
pour afficher le modèle de données. Bien sûr, cela ne va pas toujours comme prévu. C'est pourquoi nous proposons un ensemble de outils avancés de prendre plus de contrôle sur les données qui seront sélectionnées par kimono. Nous ajoutons de nouvelles fonctionnalités en mode avancé tout le temps, donc, attention, nos feature releases ou nous envoyer une note à features@kimonolabs.com si vous avez des suggestions ou des demandes.
Bien sûr, cela ne va pas toujours comme prévu. C'est pourquoi nous proposons un ensemble de outils avancés de prendre plus de contrôle sur les données qui seront sélectionnées par kimono. Nous ajoutons de nouvelles fonctionnalités en mode avancé tout le temps, donc, attention, nos feature releases ou nous envoyer une note à features@kimonolabs.com si vous avez des suggestions ou des demandes.Aperçu des données
Après que vous avez fait toutes vos sélections et nommé vos types de données et collections, vous pouvez prévisualiser vos données en cliquant sur lebouton. Les données peuvent être visionnés ou téléchargés au format JSON, CSV ou RSS.
Création de votre API
Enfin, cliquez surle nom de votre API et sélectionnez un calendrier sur lequel vous voulez mettre à jour.Notez que si vous sélectionnez en temps réel, l'API va chercher de nouvelles données à partir de la page cible chaque fois que vous touchez le point final qui peut prendre quelques secondes pour répondre à des données. Vos appels API répondront beaucoup plus rapide avec les données des API qui s'exécutent sur le calendrier (c.-à-horaire) depuis kimono répond instantanément à la version mise en cache des données.
C'est tout. Vous venez de créer votre première API. Cliquez sur le lien affiché accéder à la page de détail de l'API. Vous pouvez voir tous vos API en allant à 'Mon API "dans le menu sous votre nom.
mercredi 15 octobre 2014
J'ai du Bon DATA
Quand la transparence de la vie politique vire à la mauvaise blague
L'open data, une "opportunité unique" de donner "de nouveaux pouvoirs à la société civile, que nous demandent nos concitoyens".
La phrase est de Marilyse Lebranchu, ministre de la réforme de l'Etat,
le 24 avril. Et lorsqu'on y repense, alors qu'on s'escrime à transcrire,
classer et saisir les déclarations d'intérêts des élus français, elle
prête à sourire. Jaune.
L'open data, la libération des données, la transparence, sont
réclamées, massivement, par nos concitoyens. La gauche l'a très
longtemps professé lorsqu'elle était dans l'opposition. Mais si
certaines branches de l'Etat font de réels efforts de mise à disposition
de données, le moins que l'on puisse dire concernant la transparence
des élus est, pour paraphraser l'un d'eux, que "la route est droite, mais la pente est forte".
Avec les déclarations d'intérêts, comme nous l'avions déjà pointé en juin pour les ministres, on sombre dans le ridicule :
Là où c'est une règle déjà instaurée dans la plupart des démocraties,
en France, il aura fallu attendre l'affaire Cahuzac et l'année 2014
pour que soit instaurée une "Haute Autorité de la transparence de la vie
publique" (HATVP) chargée de recenser les déclarations d'intérêts des
parlementaires français.
Mais, alors que l'Etat est capable, avec data.gouv.fr,
de mettre en place une plateforme moderne, offrant à tout citoyen des
fichiers de données dans des formats numériques exploitables de manière
statistique et informatique, la HATVP prête elle aussi à sourire très
jaune : elle vient, en guise de déclaration d'intérêts, de livrer... un
millier de fichiers PDF, l'équivalent numérique d'une photocopie
contenant des déclarations de patrimoine remplies à la main par les
élus.
Pattes de mouches, chiffres illisibles et qui débordent du cadre,
tout semble fait pour que le citoyen, le journaliste, aient les pires
difficultés à tirer quelque chose de ce fatras. Jugez plutôt avec, au
hasard, la déclaration de Denis Baupin, député de Paris.

Ou cette autre, du député PS Eric Jalton, qui se passe de commentaire.

Ne parlons même pas de la mauvaise foi évidente de nombreux parlementaires, qui griffonnent, annotent, commentent tels des professeurs le formulaire qu'on leur demande de remplir.
Pis : aucune consigne n'est respectée. Brut, net, revenus 2012 ou
2013, chaque député semble avoir fait sa petite affaire et noté un peu
ce qu'il voulait bien dire, sans aucune méthodologie.

On ne peut pas blâmer la HATVP : son président, Jean-Louis Nadal, a
été nommé fin décembre, dans la foulée de la loi "transparence d'octobre
2013", et a dû récolter à la hâte et sans guère de moyens (elle a un
effectif d'une quinzaine de personnes et un budget minimal) les
déclarations d'intérêt des parlementaires, qui devaient rendre leur
copie avant la fin du mois de janvier.
La HATVP avait la possiblité de tout ressaisir à la main, mais cela
aurait pris des semaines. Ils ont donc privilégié l'accès à
l'information sur sa normalisation. Ils indiquent désormais réfléchir à
un système de télédéclarations, qui devrait être en place en 2015. En
attendant, il faudra se contenter de ces PDF mal écrits.
Les graphologues y verront sans doute une occasion unique de
s'intéresser à l'écriture manuscrite de nos élus et à ce qu'elle peut
révéler de leur psychologie. Tous ceux qui comptaient, à partir de ces
données, apprendre des choses sur les activités annexes des
parlementaires, sur les personnes qu'ils emploient et surtout sur leurs
conflits d'intérêts, en seront pour leurs frais.
On se souvient déjà, il y a quelques mois, de l'amère affaire des déclarations de patrimoine des élus. Certes,
on peut les consulter. Mais uniquement celle du député de sa
circonscription. En se rendant physiquement en préfecture pour la lire.
Sans avoir le droit de la photographier. Ni de prendre de notes. Et hors
de question de réaliser le moindre travail statistique sur le
patrimoine des élus : nous risquons une amende. Bref, la transparence
est des plus opaques.
Evidemment, nous n'allons pas nous contenter de nous plaindre. Avec l'association Regards citoyens, qui milite pour la transparence de la vie publique, nous allons demander à nos lecteurs et nos internautes de nous aider à transcrire ces pattes de mouches en fichiers propres et exploitables.
Mais que de temps, d'énergie perdus et surtout que de mauvaise foi dans
ces milliers de documents manuscrits balancés en guise de
"transparence" financière ! Encore une fois, la France a du chemin à
faire avant de parvenir à la cheville de ses voisins en matière de
modernité démocratique.
Samuel Laurent
Glossaire semaine 2
Glossaire
Unités arbitraires : Unité,
utilisée très souvent dans un graphe, pour donner seulement la
proportion des valeurs, sans aucune importance sur la quantité
correspondante à l’unité (source: Wiktionnary).
Carte choroplèthe : Une carte choroplèthe est une carte thématique où les régions sont colorées ou remplies d'un motif qui montre une mesure statistique, tels la densité de population ou le revenu par habitant (source: Wikipédia).
Un exemple de carte choroplète: Le PIB par habitant en 2009
{kind=link}
Projection mercator : La
projection mercator est la projection par défaut dans la plupart des
logiciels de cartographie. Elle déforme très largement les échelles près
des pôles.
Système d’information géographique (SIG ou GIS) : Un
système d’information géographique est un logiciel permettant de
traiter des informations géographiques avec une latitude et une
longitude.
CSV : CSV
signifie Comma Separated Values (valeurs séparées par des virgules).
C’est un format ouvert pour stocker des données dans un tableau.
Le tableau suivant :
Personne
|
Genre
|
Taille
|
Poids
|
Âge
|
Amin
|
masculin
|
160
|
72
|
44
|
Peut se stocker au format CSV de la manière suivante :
Personne,Genre,Taille,Poids,Âge
Amin,masculin,160,72,44
Stock : En
statistique, un stock est une valeur à un instant t, par opposition à
un flux. Cela peut désigner une quantité de marchandise dans un entrepôt
ou un patrimoine, par exemple.
Flux : Un
flux est une valeur récurrente, par opposition à un stock. Un flux peut
être un salaire, une mesure de produit intérieur brut ou un loyer, par
exemple.
Tax Freedom Day : Le
“jour de libération” fiscale est le premier jour de l'année à partir
duquel les contribuables d'un pays ont accumulé suffisamment d'argent
pour pouvoir payer les prélèvements obligatoires dont ils sont
débiteurs. C'est une illustration simplifiée du taux moyen d'imposition (source: Wikipédia).
Distribution : Une distribution statistique montre comment les points de données sont répartis. On la visualise avec un histogramme.
Variance : La
variance est un concept de statistique qui indique dans quelle mesure
les valeurs sont dispersées autour de la moyenne. Les séries de données 1
et 2 ci-dessous ont la même moyenne, mais la variance est bien plus
élevée dans la série 1.
Série 1
|
Série 2
|
1
|
5
|
2
|
6
|
3
|
5
|
4
|
4
|
5
|
5
|
6
|
6
|
7
|
6
|
8
|
4
|
9
|
4
|
5
|
5
|
7.5
|
0.75
|
Dictionnaire (jeu de données) : Le
dictionnaire d’un jeu de données est un fichier ou une feuille séparée
qui contient la signification précise des en-têtes du jeu de données.
Graphique en lignes : Un
graphique en ligne représente une série de données par des points sur
un plan à deux dimensions reliés entre eux par des droites. La dimension
représentée sur l’axe des ordonnées (X) est souvent une dimension
temporelle.
Graphique circulaire : Un
graphique circulaire représente une série de données dans un cercle
divisé en plusieurs parts dont la taille est proportionnelle à la valeur
représentée. On appelle souvent ce graphique un camembert.
Graphique en barre : Un
graphique en barre représente une série de données par une suite de
barres verticales ou horizontales dont la taille est proportionnelle à
la valeur représentée.
Histogramme : Un
histogramme est un graphique en barres (le plus souvent verticales)
représentant une distribution. La pyramide des âges est une exception:
cette distribution de la population par classe d’âge est représentée par
des barres horizontales.
jeudi 9 octobre 2014
mardi 7 octobre 2014
Mirko Lorenz.
Attraper des données sur le Web et les visualiser en un clin d’œil
Une application allemande simplifie à l’extrême la visualisation de données sur l’internet… et pourrait du même coup démocratiser le Data Journalisme en France.
D.R.")
Nicolas Kayser-Bril, CEO de J++. (c)D.R.
ABZV, un centre de formation pour journalistes en Allemagne, lance DataWrapper, une application Web de visualisation de données sur une idée du journaliste germanique Mirko Lorenz. En pratique, le service est gratuit et en ligne, il offre la possibilité aux inscrits de créer des visualisations interactives à partir de n’importe quel "jeu de données" (un tableau contenant des données chiffrées) récolté sur le Web. L’interface est rudimentaire mais ergonomique. En gros, l’utilisateur y copie/colle ses chiffres et lance l’analyse. « Quinze secondes plus tard, les chiffres réapparaissent sous la forme graphique d’un diagramme, d’un camembert ou encore d’une courbe », explique Nicolas Kayser-Bril, CEO de Journalisme++, un éditeur d’application de visualisation de données et prestataire pour le développement de DataWrapper. « Toutes les options ont été réduites au minimum afin de privilégier la rapidité d’exécution. Ce qui compte également, c’est que l’application soit facile à utiliser. »
 afin de désactiver les courbes et de les regarder ensuite une par une).")
Exemple de graphique Music Matching
Un nouveau mode d’enquête. Il faut environ une demie heure pour se familiariser avec le Soft et, au final, il y a deux manières de l’utiliser. La première solution consiste à travailler avec un jeu de données personnelles récoltées au cours d’une enquête. Au moment de la collecte, le journaliste doit alors s’assurer qu’il dispose, pour chaque chiffre, d’une valeur de référence, d’une unité de mesure bien définie et de données contextuelles comme une zone géographique ou une population donnée. Une bonne pratique consiste également à compiler le tout dans un logiciel de tableur. Seconde manière d’utiliser DataWrapper : mener des investigations au hasard dans les documents qui "traînent" sur le net. Il y en a par exemple sur le site data.gouv mais également dans certaines parties cachées des serveurs du net. Taper filetype:xls dans le moteur de recherche de Google donne parfois des résultats.
 afin de désactiver les courbes et de les regarder ensuite une par une).")
Exemple de graphique - Répartition des entreprises par effectifs en France
Renouer avec les chiffres. Visualiser les données récoltées aide le journaliste à organiser sa réflexion et enrichit son enquête. Récemment, des journalistes allemands ne s’y sont pas trompés. « Je leur ai montré l’application… Le lendemain ils intégraient de la visualisation de données dans leurs articles », se félicite Nicolas Kayser-Bril. « Le secret de l’application, c’est de simplifier le travail du journaliste sans qu’il n’ait jamais à se soucier de la technique. » Cerise sur le gâteau : le graphique interactif généré par l’application est exportable vers un blog et dispose même d’une pleine page internet, accessible par son adresse URL (voir les exemples ci-contre). « Les données racontent des histoires. »De quoi donner envie aux journalistes de se réconcilier avec les chiffres.
© Guillaume Pierre
La méthode étape par étape
Datajournalisme c'est quoi ?
Datajournalisme ?
Le mot « datajournalisme » vous est inconnu ou reste flou ? Cette page vous explique pourquoi c’est un sujet incontournable aujourd’hui pour les médias numériques.
Découvrez d’abord la définition du « datajournalisme » donnée par Estelle Prusker-Deneuville, enseignante-chercheuse en datajournalisme et responsable de l’enseignement médias à SciencesCom – Audencia Group à Nantes.
Si on synthétise, le datajournalisme, c’est une nouvelle forme de traitement de l’information où le journaliste part de données pour les transformer en une visualisation graphique attractive pour le lecteur.
Objectif : Transformer des données en une application interactive
Le datajournalisme est le processus qui amène à la fabrication d’une visualisation de données, plus couramment appelée « dataviz ».
Trois vidéos intéressantes pour comprendre l’intérêt du datajournalisme :
Trois approches différentes : celle du codeur Nicolas Kayser-Bril, celle du designeur Manuel Lima et celle du journaliste Simon Rogers.
L’intervention de Nicolas Kayser-Bril (ex-Owni et fondateur de journalism++) au TEDx de Carthage :
« Les datajournalistes sont les nouveaux punks », l’intervention de Simon Rogers – journaliste au Guardian – au TEDx du Panthéon-Sorbonne :
Manuel Lima est designer d’interaction et parle de l’importance de visualiser les données :
Quelques travaux de datavisualisations qui valent le coup d’œil :
Le datajournalisme en perspective
Le datajournalisme en perspective
En août 2010, des collègues du Centre
européen du journalisme et moi-même avons organisé à Amsterdam ce
qui fut selon nous l’une des premières conférences internationales sur
le datajournalisme. À cette époque, pas grand monde ne parlait du
sujet et il n’existait qu’une poignée d’organisations connues pour leur
travail dans ce domaine.
La manière dont certaines organisations médiatiques comme The Guardian ou The New York Times
ont géré l’énorme quantité de données publiées par Wikileaks a
largement contribué à démocratiser le terme datajournalisme, qui est
alors rentré dans l’usage (avec « journalisme assisté par ordinateur
») pour décrire l’utilisation de données dans le but d’améliorer la
couverture journalistique et d’enquêter en profondeur sur un sujet
donné. En parlant à des datajournalistes et à des journalistes
expérimentés sur Twitter, il semblerait que l’une des toutes
premières formulations de ce que nous appelons maintenant
datajournalisme ait été produite en 2006 par Adrian Holovaty,
créateur d’EveryBlock, un service d’information permettant aux
utilisateurs de savoir ce qu’il se passe dans leur quartier, leur «
pâté de maisons ». Dans son court essai intitulé Un changement fondamental à apporter aux sites d’information,
il enjoint les journalistes à publier des données structurées et
lisibles par des machines pour accompagner le traditionnel « gros pavé
de texte » :
Par exemple, supposons qu’un journal ait écrit un article sur un incendie local. Je peux lire cet article sur mon téléphone portable, hourra, vive la technologie ! Mais ce que je veux vraiment pouvoir faire, c’est explorer les faits bruts de cette histoire un par un, avec des couches d’attribution et une infrastructure permettant de comparer les détails de l’incendie avec ceux d’incendies précédents : date, heure, lieu, victimes, numéro de la caserne de pompiers, distance de la caserne, nom et nombre d’années d’expérience de chaque pompier présent sur les lieux, temps mis par les pompiers pour arriver sur place, et les incendies ultérieurs, le cas échéant.
Mais quelle est la différence avec d’autres formes de journalisme
qui se servent de bases de données ou d’ordinateurs ? Comment, et dans
quelle mesure le datajournalisme est-il différent d’autres formes de
journalisme du passé ?
Journalisme assisté par ordinateur et journalisme de précision
Cela fait un certain temps que l’on utilise des données pour
améliorer les reportages et fournir des informations structurées (si
ce n’est interprétables par des machines) au public. La discipline qui
se rapproche peut-être le plus directement de ce que nous appelons
aujourd’hui datajournalisme est le journalisme assisté par ordinateur,
ou JAO, qui fut la première approche organisée et systématique
employant des ordinateurs pour recueillir et analyser des données dans
le but d’améliorer l’information.
Le JAO fut utilisé pour la première fois en 1952 par CBS pour
prédire les résultats de l’élection présidentielle américaine.
Depuis les années 1960, des journalistes (principalement des
journalistes d’investigation américains) ont cherché à assurer un
contrôle indépendant du pouvoir en analysant des bases de données
publiques à l’aide de méthodes scientifiques. Les promoteurs de ces
techniques assistées par ordinateur, également connues sous le nom de «
journalisme de service public », se sont attachés à rapporter les
tendances, défaire les mythes populaires et révéler les injustices
perpétrées par les autorités publiques et les entreprises privées.
Par exemple, Philip Meyer a cherché à démystifier la lecture
officielle des émeutes de 1967 à Detroit en démontrant que les
manifestants n’étaient pas uniquement des migrants du Sud faiblement
éduqués. Dans les années 1980, le dossier « The Color of Money » de
Bill Dedman a révélé une discrimination raciale systémique en
matière de crédit dans les plus grandes institutions financières.
Dans son article « What Went Wrong », Steve Doig a cherché à analyser
l’étendue des dégâts provoqués par l’ouragan Andrew au début des
années 1990 pour comprendre l’impact des mauvaises pratiques et
politiques en matière de développement urbain. Le journalisme axé sur
des données s’est avéré être un service public précieux, et a
rapporté des prix prestigieux à ses pratiquants.
Au début des années 1970, l’expression « journalisme de précision »
a été inventée pour décrire cette méthode de collecte
d’informations : « l’application de méthodes de recherche issues des
sciences sociales et comportementales à la pratique du journalisme »
(extrait du livre The New Precision Journalism
de Philip Meyer). Le journalisme de précision était perçu comme
étant pratiqué dans les institutions médiatiques dominantes par des
professionnels formés au journalisme et aux sciences sociales. Il est
né en réponse au « nouveau journalisme », une forme de journalisme qui
appliquait des techniques de fiction au reportage. Meyer suggère que
les techniques scientifiques de collecte et d’analyse de données sont
préférables aux techniques littéraires pour aider le journalisme dans
sa quête d’objectivité et de vérité.
Le journalisme de précision peut être vu comme une réaction aux
insuffisances et aux faiblesses souvent prêtées au journalisme :
dépendance aux communiqués de presse (plus tard qualifié de «
churnalism », ou journalisme prémâché), influence des sources
d’autorité, etc. D’après Meyer, ces problèmes résultent d’un manque
d’application de techniques des sciences de l’information et de
méthodes scientifiques telles que les sondages et les archives
publiques. Le journalisme de précision, tel qu’il était pratiqué dans
les années 1960, servait à représenter des groupes marginaux.
D’après Meyer :
Le journalisme de précision était une façon d’élargir la boîte à outils du reporter pour lui permettre de couvrir des sujets auparavant inaccessibles, du moins dans leur forme brute. Il était particulièrement utile pour donner une voix aux minorités et aux groupes dissidents qui luttaient pour leur représentation.
Dans les années 1980, un article majeur portant sur la relation
entre le journalisme et les sciences sociales fait écho au discours
actuel sur le datajournalisme. Les auteurs, deux professeurs de
journalisme américains, suggèrent qu’au cours des années 1970 et
1980, la conception publique de l’information a évolué d’une notion
plus restreinte de journalisme « factuel » vers un journalisme «
situationnel ». Par exemple, en utilisant des données de recensement ou
des sondages, les journalistes peuvent « dépasser le spectre
d’évènements spécifiques et isolés afin de fournir un contexte qui
leur donne un sens ».
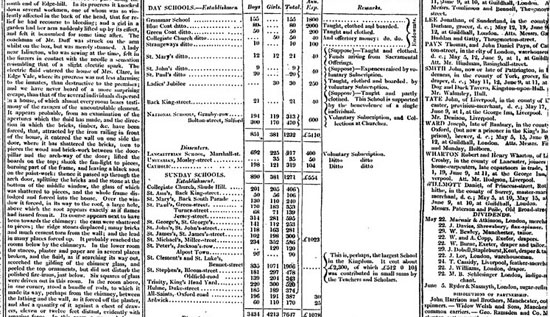
Datajournalisme dans le Guardian en 1821 (The Guardian)
Comme on peut l’imaginer, l’utilisation de données dans le but
d’améliorer les reportages remonte aussi loin que les données
existent. Comme le fait remarquer Simon Rogers, le premier exemple de
datajournalisme au Guardian date de 1821. Il s’agit d’un listing « volé
» dévoilant le nombre d’élèves et le coût de la scolarité dans
chaque école de Manchester. D’après Rogers, il avait permis de
déterminer le véritable nombre d’étudiants recevant une éducation
gratuite, qui était sensiblement plus élevé que le nombre officiel.
Parmi les premiers exemples de datajournalisme en Europe, on peut
également citer Florence Nightingale et son fameux rapport intitulé «
Mortality of the British Army », publié en 1858. Dans son rapport au
Parlement, elle avait utilisé des graphiques pour plaider pour une
amélioration des services de santé dans l’armée britannique. Le plus
célèbre est sa « crête de coq », un diagramme circulaire en douze
sections représentant chacune un nombre de morts par mois, qui mettait
en évidence le fait que l’immense majorité des morts était imputable
à des maladies évitables plutôt qu’à des balles ennemies.
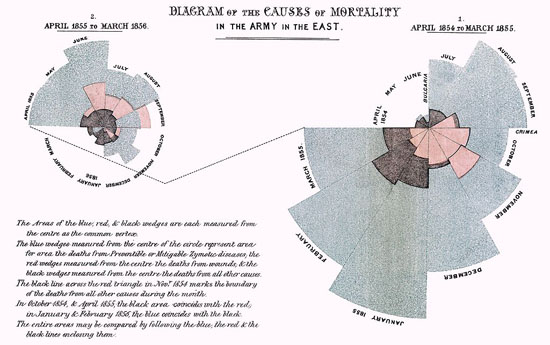
Mortalité dans l'armée britannique par Florence Nightingale (Image de Wikipedia)
Datajournalisme et journalisme assisté par ordinateur
À l’heure actuelle, il y a un débat sur l’évolution du terme «
datajournalisme » et son lien avec de précédentes pratiques
journalistiques employant des techniques informatiques pour analyser des
bases de données.
Certains prétendent qu’il y a une différence entre le JAO et le
datajournalisme. Selon eux, le JAO est une technique de collecte et
d’analyse de données tendant à améliorer les reportages
(généralement d’investigation), alors que le datajournalisme emploie
des données dans tout le workflow journalistique. En ce sens, le
datajournaliste prête autant – et parfois plus – d’attention aux
données elles-mêmes, plutôt que de simplement les utiliser pour
trouver ou enrichir des histoires. C’est ainsi que l’on voit le Datablog
du Guardian ou The Texas Tribune publier des bases de
données accompagnant leurs articles – voire des bases de données
seules – pour que tout le monde puisse les explorer et les analyser.
Une autre différence, c’est qu’auparavant, les journalistes
d’investigation souffraient du manque d’informations sur les sujets
qu’ils voulaient traiter. Bien sûr, ce problème se pose toujours
aujourd’hui, mais il y a également une surabondance d’informations dont
les journalistes ne savent pas forcément que faire. Comme exemple
récent, on pourrait citer le Combined Online Information System
(COINS), la plus grosse base de données anglaise sur les dépenses
publiques. Cette base de données était réclamée depuis longtemps par
les organisations militant pour la transparence des comptes publics,
mais elle a laissé de nombreux journalistes perplexes lors de sa
publication.
D’un autre côté, certains disent qu’il y a aucune différence de
taille entre le datajournalisme et le journalisme assisté par
ordinateur. Il est maintenant couramment admis que même les pratiques
médiatiques les plus récentes ont un héritage historique, ainsi qu’un
certain degré de nouveauté. Plutôt que de chercher à savoir si le
datajournalisme est une discipline complètement nouvelle ou non, il
serait peut-être plus profitable de le considérer comme relevant d’une
longue tradition, mais répondant à des circonstances et à des
conditions nouvelles. Même s’il n’y a pas forcément de différence en
termes d’objectifs et de techniques, l’émergence de l’étiquette «
datajournalisme » au début du siècle dénote une nouvelle phase dans
laquelle l’énorme volume de données en libre accès sur Internet –
combiné avec des outils sophistiqués axés sur l’utilisateur,
l’autopublication et le crowdsourcing – permet à de plus en plus de gens de travailler avec des données, plus facilement que jamais.
Le datajournalisme, c’est la démocratisation des données
Les technologies numériques et le Web sont en train de changer
fondamentalement notre manière de publier des informations. Le
datajournalisme n’est qu’une partie de l’écosystème d’outils et de
pratiques qui s’est développé autour des sites et des services de
données. La nature même de la structure en hyperliens du Web consiste
à citer et partager les sources, et c’est ainsi que nous avons
l’habitude de parcourir les informations aujourd’hui. Si l’on remonte
encore plus loin, le principe fondateur de la structure du Web est issu
du principe de citation utilisé dans les travaux universitaires. La
citation et le partage des matériaux sources et des données de
l’histoire est l’une des avancées principales du datajournalisme, ce
que le fondateur de WikiLeaks Julian Assange qualifie de « journalisme
scientifique ».
En permettant à tout-un-chacun de parcourir les sources des données
et de trouver les informations qui l’intéressent, mais aussi de
vérifier des assertions et de remettre en question des idées reçues,
le datajournalisme représente de fait une démocratisation de masse des
ressources, outils, techniques et méthodologies auparavant utilisés
par des spécialistes, des journalistes d’investigation, des chercheurs
en sciences sociales, des statisticiens, des analystes et autres
experts. Si, aujourd’hui, la pratique consistant à citer et à donner
le lien de ses sources de données est spécifique au datajournalisme,
nous vivons dans un monde où les données sont intégrées de façon de
plus en plus transparente au tissu des médias. Les datajournalistes
ont un rôle important à jouer dans la démocratisation des données
auprès du plus grand nombre.
Pour l’instant, la communauté naissante de personnes se réclamant
du datajournalisme est distincte de la communauté du JAO, qui est plus
mûre. Gageons qu’à l’avenir, nous verrons des liens plus étroits
s’établir entre ces deux communautés, de la même façon que nous
voyons de nouvelles ONG et des organisations médiatiques citoyennes
comme ProPublica et le Bureau of Investigative Journalism travailler
main dans la main avec des médias traditionnels pour enquêter sur
certains sujets. La communauté du datajournalisme développe peut-être
des approches plus innovantes dans sa manière de fournir des données
et de présenter des histoires, mais l’approche profondément analytique
et critique de la communauté du JAO a certainement des choses à lui
apprendre.
Liliana Bounegru, Centre européen du journalisme
Inscription à :
Articles (Atom)