Le datajournalisme en perspective
En août 2010, des collègues du Centre
européen du journalisme et moi-même avons organisé à Amsterdam ce
qui fut selon nous l’une des premières conférences internationales sur
le datajournalisme. À cette époque, pas grand monde ne parlait du
sujet et il n’existait qu’une poignée d’organisations connues pour leur
travail dans ce domaine.
La manière dont certaines organisations médiatiques comme The Guardian ou The New York Times
ont géré l’énorme quantité de données publiées par Wikileaks a
largement contribué à démocratiser le terme datajournalisme, qui est
alors rentré dans l’usage (avec « journalisme assisté par ordinateur
») pour décrire l’utilisation de données dans le but d’améliorer la
couverture journalistique et d’enquêter en profondeur sur un sujet
donné. En parlant à des datajournalistes et à des journalistes
expérimentés sur Twitter, il semblerait que l’une des toutes
premières formulations de ce que nous appelons maintenant
datajournalisme ait été produite en 2006 par Adrian Holovaty,
créateur d’EveryBlock, un service d’information permettant aux
utilisateurs de savoir ce qu’il se passe dans leur quartier, leur «
pâté de maisons ». Dans son court essai intitulé Un changement fondamental à apporter aux sites d’information,
il enjoint les journalistes à publier des données structurées et
lisibles par des machines pour accompagner le traditionnel « gros pavé
de texte » :
Par exemple, supposons qu’un journal ait écrit un article sur un incendie local. Je peux lire cet article sur mon téléphone portable, hourra, vive la technologie ! Mais ce que je veux vraiment pouvoir faire, c’est explorer les faits bruts de cette histoire un par un, avec des couches d’attribution et une infrastructure permettant de comparer les détails de l’incendie avec ceux d’incendies précédents : date, heure, lieu, victimes, numéro de la caserne de pompiers, distance de la caserne, nom et nombre d’années d’expérience de chaque pompier présent sur les lieux, temps mis par les pompiers pour arriver sur place, et les incendies ultérieurs, le cas échéant.
Mais quelle est la différence avec d’autres formes de journalisme
qui se servent de bases de données ou d’ordinateurs ? Comment, et dans
quelle mesure le datajournalisme est-il différent d’autres formes de
journalisme du passé ?
Journalisme assisté par ordinateur et journalisme de précision
Cela fait un certain temps que l’on utilise des données pour
améliorer les reportages et fournir des informations structurées (si
ce n’est interprétables par des machines) au public. La discipline qui
se rapproche peut-être le plus directement de ce que nous appelons
aujourd’hui datajournalisme est le journalisme assisté par ordinateur,
ou JAO, qui fut la première approche organisée et systématique
employant des ordinateurs pour recueillir et analyser des données dans
le but d’améliorer l’information.
Le JAO fut utilisé pour la première fois en 1952 par CBS pour
prédire les résultats de l’élection présidentielle américaine.
Depuis les années 1960, des journalistes (principalement des
journalistes d’investigation américains) ont cherché à assurer un
contrôle indépendant du pouvoir en analysant des bases de données
publiques à l’aide de méthodes scientifiques. Les promoteurs de ces
techniques assistées par ordinateur, également connues sous le nom de «
journalisme de service public », se sont attachés à rapporter les
tendances, défaire les mythes populaires et révéler les injustices
perpétrées par les autorités publiques et les entreprises privées.
Par exemple, Philip Meyer a cherché à démystifier la lecture
officielle des émeutes de 1967 à Detroit en démontrant que les
manifestants n’étaient pas uniquement des migrants du Sud faiblement
éduqués. Dans les années 1980, le dossier « The Color of Money » de
Bill Dedman a révélé une discrimination raciale systémique en
matière de crédit dans les plus grandes institutions financières.
Dans son article « What Went Wrong », Steve Doig a cherché à analyser
l’étendue des dégâts provoqués par l’ouragan Andrew au début des
années 1990 pour comprendre l’impact des mauvaises pratiques et
politiques en matière de développement urbain. Le journalisme axé sur
des données s’est avéré être un service public précieux, et a
rapporté des prix prestigieux à ses pratiquants.
Au début des années 1970, l’expression « journalisme de précision »
a été inventée pour décrire cette méthode de collecte
d’informations : « l’application de méthodes de recherche issues des
sciences sociales et comportementales à la pratique du journalisme »
(extrait du livre The New Precision Journalism
de Philip Meyer). Le journalisme de précision était perçu comme
étant pratiqué dans les institutions médiatiques dominantes par des
professionnels formés au journalisme et aux sciences sociales. Il est
né en réponse au « nouveau journalisme », une forme de journalisme qui
appliquait des techniques de fiction au reportage. Meyer suggère que
les techniques scientifiques de collecte et d’analyse de données sont
préférables aux techniques littéraires pour aider le journalisme dans
sa quête d’objectivité et de vérité.
Le journalisme de précision peut être vu comme une réaction aux
insuffisances et aux faiblesses souvent prêtées au journalisme :
dépendance aux communiqués de presse (plus tard qualifié de «
churnalism », ou journalisme prémâché), influence des sources
d’autorité, etc. D’après Meyer, ces problèmes résultent d’un manque
d’application de techniques des sciences de l’information et de
méthodes scientifiques telles que les sondages et les archives
publiques. Le journalisme de précision, tel qu’il était pratiqué dans
les années 1960, servait à représenter des groupes marginaux.
D’après Meyer :
Le journalisme de précision était une façon d’élargir la boîte à outils du reporter pour lui permettre de couvrir des sujets auparavant inaccessibles, du moins dans leur forme brute. Il était particulièrement utile pour donner une voix aux minorités et aux groupes dissidents qui luttaient pour leur représentation.
Dans les années 1980, un article majeur portant sur la relation
entre le journalisme et les sciences sociales fait écho au discours
actuel sur le datajournalisme. Les auteurs, deux professeurs de
journalisme américains, suggèrent qu’au cours des années 1970 et
1980, la conception publique de l’information a évolué d’une notion
plus restreinte de journalisme « factuel » vers un journalisme «
situationnel ». Par exemple, en utilisant des données de recensement ou
des sondages, les journalistes peuvent « dépasser le spectre
d’évènements spécifiques et isolés afin de fournir un contexte qui
leur donne un sens ».
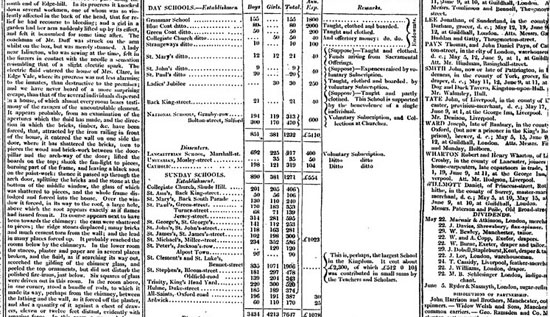
Datajournalisme dans le Guardian en 1821 (The Guardian)
Comme on peut l’imaginer, l’utilisation de données dans le but
d’améliorer les reportages remonte aussi loin que les données
existent. Comme le fait remarquer Simon Rogers, le premier exemple de
datajournalisme au Guardian date de 1821. Il s’agit d’un listing « volé
» dévoilant le nombre d’élèves et le coût de la scolarité dans
chaque école de Manchester. D’après Rogers, il avait permis de
déterminer le véritable nombre d’étudiants recevant une éducation
gratuite, qui était sensiblement plus élevé que le nombre officiel.
Parmi les premiers exemples de datajournalisme en Europe, on peut
également citer Florence Nightingale et son fameux rapport intitulé «
Mortality of the British Army », publié en 1858. Dans son rapport au
Parlement, elle avait utilisé des graphiques pour plaider pour une
amélioration des services de santé dans l’armée britannique. Le plus
célèbre est sa « crête de coq », un diagramme circulaire en douze
sections représentant chacune un nombre de morts par mois, qui mettait
en évidence le fait que l’immense majorité des morts était imputable
à des maladies évitables plutôt qu’à des balles ennemies.
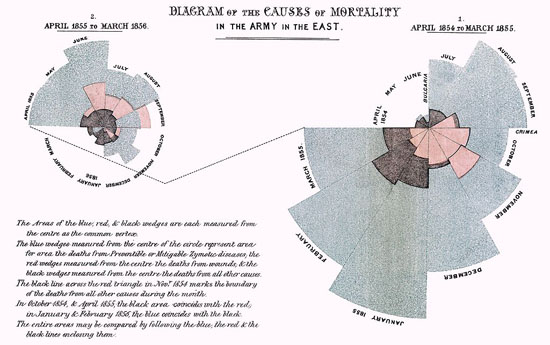
Mortalité dans l'armée britannique par Florence Nightingale (Image de Wikipedia)
Datajournalisme et journalisme assisté par ordinateur
À l’heure actuelle, il y a un débat sur l’évolution du terme «
datajournalisme » et son lien avec de précédentes pratiques
journalistiques employant des techniques informatiques pour analyser des
bases de données.
Certains prétendent qu’il y a une différence entre le JAO et le
datajournalisme. Selon eux, le JAO est une technique de collecte et
d’analyse de données tendant à améliorer les reportages
(généralement d’investigation), alors que le datajournalisme emploie
des données dans tout le workflow journalistique. En ce sens, le
datajournaliste prête autant – et parfois plus – d’attention aux
données elles-mêmes, plutôt que de simplement les utiliser pour
trouver ou enrichir des histoires. C’est ainsi que l’on voit le Datablog
du Guardian ou The Texas Tribune publier des bases de
données accompagnant leurs articles – voire des bases de données
seules – pour que tout le monde puisse les explorer et les analyser.
Une autre différence, c’est qu’auparavant, les journalistes
d’investigation souffraient du manque d’informations sur les sujets
qu’ils voulaient traiter. Bien sûr, ce problème se pose toujours
aujourd’hui, mais il y a également une surabondance d’informations dont
les journalistes ne savent pas forcément que faire. Comme exemple
récent, on pourrait citer le Combined Online Information System
(COINS), la plus grosse base de données anglaise sur les dépenses
publiques. Cette base de données était réclamée depuis longtemps par
les organisations militant pour la transparence des comptes publics,
mais elle a laissé de nombreux journalistes perplexes lors de sa
publication.
D’un autre côté, certains disent qu’il y a aucune différence de
taille entre le datajournalisme et le journalisme assisté par
ordinateur. Il est maintenant couramment admis que même les pratiques
médiatiques les plus récentes ont un héritage historique, ainsi qu’un
certain degré de nouveauté. Plutôt que de chercher à savoir si le
datajournalisme est une discipline complètement nouvelle ou non, il
serait peut-être plus profitable de le considérer comme relevant d’une
longue tradition, mais répondant à des circonstances et à des
conditions nouvelles. Même s’il n’y a pas forcément de différence en
termes d’objectifs et de techniques, l’émergence de l’étiquette «
datajournalisme » au début du siècle dénote une nouvelle phase dans
laquelle l’énorme volume de données en libre accès sur Internet –
combiné avec des outils sophistiqués axés sur l’utilisateur,
l’autopublication et le crowdsourcing – permet à de plus en plus de gens de travailler avec des données, plus facilement que jamais.
Le datajournalisme, c’est la démocratisation des données
Les technologies numériques et le Web sont en train de changer
fondamentalement notre manière de publier des informations. Le
datajournalisme n’est qu’une partie de l’écosystème d’outils et de
pratiques qui s’est développé autour des sites et des services de
données. La nature même de la structure en hyperliens du Web consiste
à citer et partager les sources, et c’est ainsi que nous avons
l’habitude de parcourir les informations aujourd’hui. Si l’on remonte
encore plus loin, le principe fondateur de la structure du Web est issu
du principe de citation utilisé dans les travaux universitaires. La
citation et le partage des matériaux sources et des données de
l’histoire est l’une des avancées principales du datajournalisme, ce
que le fondateur de WikiLeaks Julian Assange qualifie de « journalisme
scientifique ».
En permettant à tout-un-chacun de parcourir les sources des données
et de trouver les informations qui l’intéressent, mais aussi de
vérifier des assertions et de remettre en question des idées reçues,
le datajournalisme représente de fait une démocratisation de masse des
ressources, outils, techniques et méthodologies auparavant utilisés
par des spécialistes, des journalistes d’investigation, des chercheurs
en sciences sociales, des statisticiens, des analystes et autres
experts. Si, aujourd’hui, la pratique consistant à citer et à donner
le lien de ses sources de données est spécifique au datajournalisme,
nous vivons dans un monde où les données sont intégrées de façon de
plus en plus transparente au tissu des médias. Les datajournalistes
ont un rôle important à jouer dans la démocratisation des données
auprès du plus grand nombre.
Pour l’instant, la communauté naissante de personnes se réclamant
du datajournalisme est distincte de la communauté du JAO, qui est plus
mûre. Gageons qu’à l’avenir, nous verrons des liens plus étroits
s’établir entre ces deux communautés, de la même façon que nous
voyons de nouvelles ONG et des organisations médiatiques citoyennes
comme ProPublica et le Bureau of Investigative Journalism travailler
main dans la main avec des médias traditionnels pour enquêter sur
certains sujets. La communauté du datajournalisme développe peut-être
des approches plus innovantes dans sa manière de fournir des données
et de présenter des histoires, mais l’approche profondément analytique
et critique de la communauté du JAO a certainement des choses à lui
apprendre.
Liliana Bounegru, Centre européen du journalisme
Aucun commentaire:
Enregistrer un commentaire